Đặt lịch
Sửa chữa
Hotline miễn phí

Chat GPT bị chặn trên nhiều trang tin tức lớn
Ngoài ra, các trang web khác như Amazon, Facebook, Rotten Tomatoes và Shutterstock cũng đang làm điều đó.
Điều này đặc biệt quan trọng vì các công ty AI không bắt buộc phải trả tiền cho nguồn để sử dụng nội dung. Các mô hình AI không phải là những người hiểu biết toàn diện như chúng ta nghĩ, chúng chỉ đang thu thập thông tin web và sử dụng nội dung của các trang khác.
Việc từ chối rộng lớn này từ các tờ báo lớn nghĩa là Chat GPT, Google Gemini, Anthropic sẽ ít nội dung hơn để cung cấp cho người dùng. Điều này có thể dẫn đến các câu trả lời sai lệch, hoặc ít nhất là điểm mù trong thông tin mà trí tuệ nhân tạo cung cấp.
Để chặn trình thu thập thông tin AI quét một trang web, nhóm kỹ thuật của trang web chỉ cần thêm một vài dòng mã đơn giản vào tệp được gọi là tệp robots.txt. Phương pháp này không mới; đó là một phương pháp đã được thiết lập để bảo mật trang web, quản lý máy chủ và kiểm soát luồng nội dung. Tuy nhiên, không phải tất cả các trang tin tức đều chặn cùng một trình thu thập dữ liệu AI.
Có 36% trong số 100 trang web hàng đầu đã chặn GPT Boot của OpenAI. Sau GPBot, trình thu thập thông tin bị cản trở nhiều nhất tiếp theo là CCBot (15%), tiếp theo là Google Extended (10%) và Anthropic AI (6%).
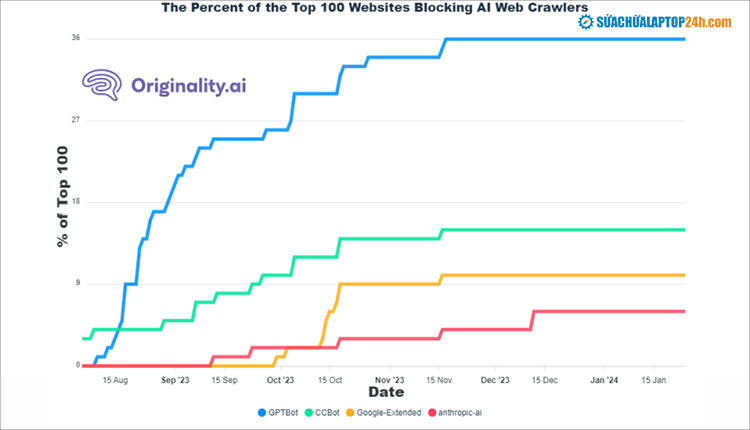
100 trang web hàng đầu chặn trình thu thập thông tin AI
Ngoài các ấn phẩm tin tức, các trang như Wikipedia, Reddit, YouTube và X/Twitter hiện không chặn GPTBot. Nội dung của họ chủ yếu do người dùng tạo và là một trò chơi công bằng khi được đưa vào câu trả lời của Chat GPT. Vì vậy, điều này đặt ra câu hỏi: Liệu các chatbot AI có thể trở thành thiên đường cho nội dung thiên về quan điểm không?
Chỉ có thời gian mới trả lời được. Hiện tại, người đọc có nghĩa vụ đặt các câu hỏi tiếp theo và tìm hiểu sâu hơn để xác thực thông tin.
(Theo PCmag)
Tin hot
Đặt lịch










![[Tổng hợp] 50+ hình nền đen hiện đại, chất lượng cao](https://suachualaptop24h.com/images/news/2021/03/31/small/tong-hop-50-hinh-nen-den-bao-dep-va-chat-luong_1617134787.jpg)


![[Tổng hợp] 50+ hình nền capybara cute HD, 4K chất lượng cao](https://suachualaptop24h.com/images/news/2024/07/10/small/hinh-nen-capybara-cute-4k-cho-dien-thoai-may-tinh_1720594478.jpg)